はじめまして。5月に入社したryohei515です。
前職ではOracleを使ってSQLを書く機会がよくあり、パフォーマンスチューニング等も行ってきました。
インゲージに入社してからSQLを書く機会があったのですが、DBがPostgreSQLであるため、これまで使っていた細かなSQLのパフォーマンスの小技がPostgreSQLでも通用するのか気になり、検証してみました。
環境準備
Dockerを使って、PostgreSQLのコンテナを作成します。最新の13.3を使用しています。
ちょっと検証したい時に、ローカルを汚さずに簡単に環境が作れるので便利ですね!
docker run --rm -d -p 15432:5432 -v postgres-tmp:/var/lib/postgresql/data -e POSTGRES_HOST_AUTH_METHOD=trust postgres:13.3
※ パフォーマンスを見たいだけなので、パスワード不要となるよう、POSTGRES_HOST_AUTH_METHODはtrueに設定しました。
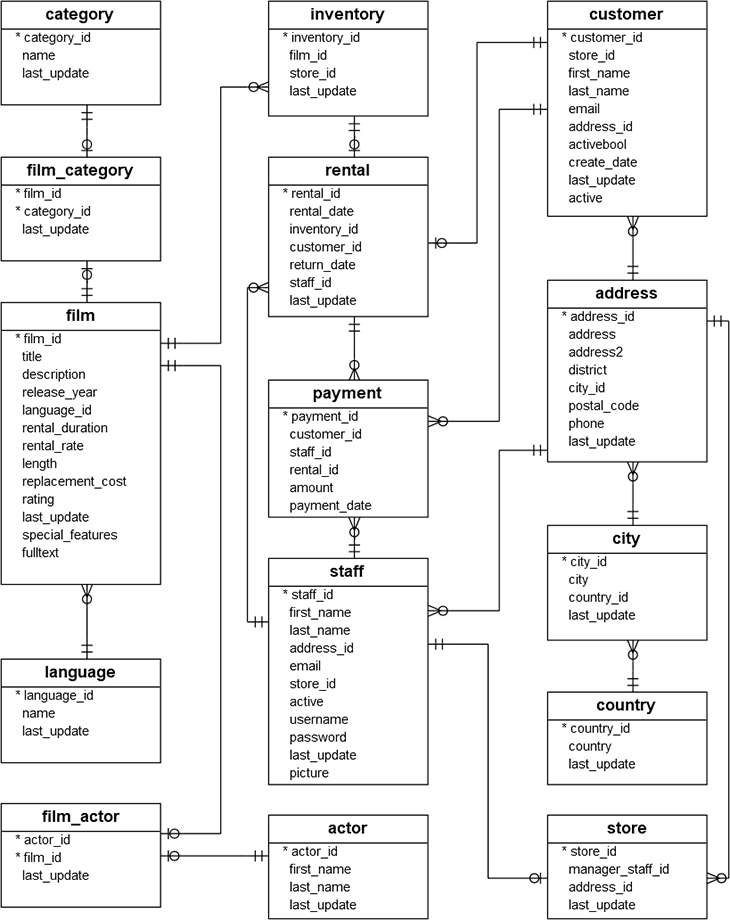
今回の検証用のデータは、postgrteSQLのTutorialで提供されている、dvdrentalを使用しようと思います。
ER図も用意されており、SQLの動作確認や学習なんかにも使えそうですね。
データ登録の前に、事前にDATABASEを作成しておきます。
psql -h localhost -p 15432 -U postgres -c "CREATE DATABASE dvdrental;"
以下のサイトよりzipファイルをダウンロードし、ダウンロードしたディレクトリに移動します。
ダウンロードファイルを、unzipコマンドで展開し、.tarのファイルを作成します。
$ unzip ./dvdrental.zip Archive: /Users/makabe/Library/Mobile Documents/com~apple~CloudDocs/Documents/memo/091_blog/20210719_SQL_performance/dvdrental.zip inflating: dvdrental.tar
事前に作成しておいたDBに、以下のコマンドでデータ作成します。
(特にメッセージ等表示されず、完了します。)
pg_restore -U postgres -d dvdrental -h localhost -p 15432 ./dvdrental.tar
これで以下のコマンドを打ち込めば準備完了です。
psql -h localhost -p 15432 -U postgres -d dvdrental
パフォーマンスチェック
環境は準備できたので、パフォーマンスを測ってみたいと思います。
「EXISTSではなくINNER JOINを使う」というのを、これまでよく使っていたので、実行時間やコストにどんな差が出るか見てみます。
(ざっと検索してみたところ、PostgreSQLでも同じそう…)
SQLの内容は、Rentalテーブルのデータで、length > 100のFilmがどれだけあるかという内容で見ていきます。
EXISTSで書いてみるとこんな感じ。
select r.* from rental r where exists( select 1 from inventory i inner join film f on i.film_id = f.film_id where 1=1 and r.inventory_id = i.inventory_id and f.length > 100 )
INNER JOINで書いてみるとこんな感じかと思います。
select r.* from rental r inner join inventory i on r.inventory_id = i.inventory_id inner join film f on i.film_id = f.film_id where 1=1 and f.length > 100 ;
PostgreSQLでは、SQLの頭にEXPLAIN ANALYZEをつけることで、実行計画を見ることができるので、それぞれ出力してみるとこうなりました。
EXISTS
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Hash Semi Join (cost=191.88..653.14 rows=9771 width=36) (actual time=4.001..12.163 rows=9723 loops=1)
Hash Cond: (r.inventory_id = i.inventory_id)
-> Seq Scan on rental r (cost=0.00..310.44 rows=16044 width=36) (actual time=0.014..2.067 rows=16044 loops=1)
-> Hash (cost=157.00..157.00 rows=2790 width=4) (actual time=3.915..3.918 rows=2785 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 130kB
-> Hash Join (cost=74.11..157.00 rows=2790 width=4) (actual time=0.564..2.816 rows=2785 loops=1)
Hash Cond: (i.film_id = f.film_id)
-> Seq Scan on inventory i (cost=0.00..70.81 rows=4581 width=6) (actual time=0.016..0.662 rows=4581 loops=1)
-> Hash (cost=66.50..66.50 rows=609 width=4) (actual time=0.512..0.514 rows=610 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 30kB
-> Seq Scan on film f (cost=0.00..66.50 rows=609 width=4) (actual time=0.007..0.354 rows=610 loops=1)
Filter: (length > 100)
Rows Removed by Filter: 390
Planning Time: 2.396 ms
Execution Time: 12.817 ms
(15 rows)
INNER JOIN
------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=172.62..596.63 rows=5343 width=36) (actual time=3.954..10.271 rows=9723 loops=1)
Hash Cond: (r.inventory_id = i.inventory_id)
-> Seq Scan on rental r (cost=0.00..310.44 rows=16044 width=36) (actual time=0.011..1.635 rows=16044 loops=1)
-> Hash (cost=153.55..153.55 rows=1525 width=4) (actual time=3.892..3.895 rows=2785 loops=1)
Buckets: 4096 (originally 2048) Batches: 1 (originally 1) Memory Usage: 130kB
-> Hash Join (cost=70.66..153.55 rows=1525 width=4) (actual time=0.609..3.106 rows=2785 loops=1)
Hash Cond: (i.film_id = f.film_id)
-> Seq Scan on inventory i (cost=0.00..70.81 rows=4581 width=6) (actual time=0.013..0.632 rows=4581 loops=1)
-> Hash (cost=66.50..66.50 rows=333 width=4) (actual time=0.572..0.574 rows=610 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 30kB
-> Seq Scan on film f (cost=0.00..66.50 rows=333 width=4) (actual time=0.012..0.409 rows=610 loops=1)
Filter: (length > 100)
Rows Removed by Filter: 390
Planning Time: 1.070 ms
Execution Time: 10.788 ms
(15 rows)
Rentalの件数が16000件しかないので、大した違いはありませんが、Planning TimeとExecution TimeともにINNER JOINのSQLの方が速いことがわかります。
各SQLの実行計画で主に違う点は、一番上の計画のようです。
Hash Semi Join (cost=191.88..653.14 rows=9771 width=36) # EXISTS Hash Join (cost=172.62..596.63 rows=5343 width=36) # INNER JOIN
- cost
- 左側の数字: 初期処理の推定コスト。 出力段階が開始できるようになる前に消費される時間。
- 右側の数字: 全体推定コスト。
- rows: 行の推定数。
- width: 行のバイト単位の長さ。
ここでもコストが初期処理の推定コスト・全体推定コスト共にINNER JOINの方が小さく、これが処理時間の違いにつながったのかと思います。
rowsが異なるのは、あくまで推定値だからということでしょうか。
まとめ
環境構築して実行したSQLの実行計画より、INNER JOINの方がEXISTSより早いことを確認することができました。
ただINNER JOINだと、SQLを読む側にとって抽出条件と分かりにくいので、件数が少ないようなテーブルであれば、EXISTSの方がよいでしょう。ケースバイケースですね。
また、PostgreSQLのTutorialのデータ量だと、パフォーマンスも問題にならず、時間がかかると実感できなかったので、同様のことをする機会があれば、今度はデータ量をもっと多くして試してみたいと思います。