皆さんこんにちは。wasatingです。
ここしばらく生成モデル関連の話があちこちでされ、ChatGPTをはじめとして、大きな流れができているなあと思っています。
また、HuggingFaceに日本語向けでオープン化されたGPTシリーズがアップロードされるなど、個人で使える状況が整備されていますね。
ちなみに弊社サービスのRe:lationでも例にもれずサービスに利用できないかと考え、ChatGPT APIを用いて問い合わせの要約機能を実装しています。
さて、上記したオープン化されたGPTですが、個人で使えるとはいえ、レスポンスにかかる時間を考慮したうえで使える状況にするためには、それなりにVRAMがあるGPUが必要だったりと、そう簡単に使えるわけでもないという面もあります。
そこで今回は
1. AWS SagaMeker Studioを使って実行環境を構築し、
2. Gradioを使って簡易デモを作成
していきたいと思います。(SageMaker Studio自体はすでに使える状況を前提とします)
また、モデルはrinna/japanese-gpt-neox-3.6b-instruction-sftを使用します。
AWS SageMaker Studioを使って実行環境を構築
SageMaker StudioのLauncherからcreate notebook で notebookを作成します。
この時、change environmentから
- Image: PyTorch 2.0.0 Pyhon 3.10 GPU Optimized
- instance: ml.g4dn.xlarge
に変更しておきます。

まずは必要なパッケージをpip installしていきます
!pip install transformers==4.30.2 sentencepiece gradio
これ以降はほとんどhugging face上のドキュメントと同じように進めていきます。
一点だけ変更箇所があり、AutoModelForCausalLM.from_pretrained内でtorch_dtype=torch.float16を付け忘れるとkernelが死ぬのでご注意ください。
import torch from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft", use_fast=False) model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft", torch_dtype=torch.float16).to('cuda') prompt = [ { "speaker": "ユーザー", "text": "日本のおすすめの観光地を教えてください。" }, { "speaker": "システム", "text": "どの地域の観光地が知りたいですか?" }, { "speaker": "ユーザー", "text": "渋谷の観光地を教えてください。" } ] prompt = [ f"{uttr['speaker']}: {uttr['text']}" for uttr in prompt ] prompt = "<NL>".join(prompt) prompt = ( prompt + "<NL>" + "システム: " ) token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt") with torch.no_grad(): output_ids = model.generate( token_ids.to(model.device), do_sample=True, max_new_tokens=128, temperature=0.7, pad_token_id=tokenizer.pad_token_id, bos_token_id=tokenizer.bos_token_id, eos_token_id=tokenizer.eos_token_id ) output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):]) output = output.replace("<NL>", "\n")
性能はというといまいちちぐはぐな回答だったりもしますね…。
dtypeを変えた影響もあると思いますが、とりあえずSageMaker上で動かせることを確認できました。
Gradioを使って簡易デモを作成
Gradioは、pythonで簡単にWeb UIを作成することができるパッケージで、HuggingFaceでも使用されています。
雑に説明すると、テキストボックスやチェックボックス、スライダーなど、入力の設定箇所や、それらをもとに得た出力をページ上に表示するといったUIを作成できるといったものになります。
Gradioに関する詳細な説明は省略しますが、気になる方は公式ドキュメント等をご参照ください。
今回はGradio.Chatbotを使って簡易的なチャットボットを作っていきます。
まずはこれまでの入力とモデルの出力をもとに返答文を生成する処理を作ります。
class RinnaTalk(): def __init__(self, tokenizer=None, model=None): self.prompt = '' # 事前にmodelとtokenizerを呼んでおく self.tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft", use_fast=False) if tokenizer is None else tokenizer self.model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft", torch_dtype=torch.float16).to('cuda') if model is None else model def chat(self, message: str, chat_history: list, max_token_length: int = 128, min_token_length: int = 10, temperature: float = 0.8): # チャット履歴をクリアした際にpromptもクリアさせるため if len(chat_history) == 0: self.prompt = '' self.prompt += f'ユーザー: {message}<NL>システム: ' token_ids = self.tokenizer.encode(self.prompt, add_special_tokens=False, return_tensors="pt") with torch.no_grad(): output_ids = self.model.generate( token_ids.to(self.model.device), max_new_tokens=max_token_length, min_new_tokens=min_token_length, do_sample=True, temperature=temperature, pad_token_id=self.tokenizer.pad_token_id, bos_token_id=self.tokenizer.bos_token_id, eos_token_id=self.tokenizer.eos_token_id ) output = self.tokenizer.decode(output_ids.tolist()[0]) latest_reply = output.split('<NL>')[-1].rstrip('</s>') chat_history.append([message, latest_reply]) self.prompt += f'{latest_reply}<NL>' return "", chat_history rinna = RinnaTalk()
これでrinna/japanese-gpt-neox-3.6b-instruction-sftを使ってチャットができるようになりました。
では次にRinnaTalk.chatとGradio.Chatbotを使ってチャットボットを作っていきます。
import gradio as gr with gr.Blocks() as demo: chatbot = gr.Chatbot() max_token_length = gr.Slider(minimum=50, maximum=256, label='max_token_length') min_token_length = gr.Slider(minimum=10, maximum=128, label='min_token_length') temperature = gr.Slider(minimum=0, maximum=1, scale=0.01, value=0.8, label='temperature') msg = gr.Textbox() clear = gr.ClearButton([msg, chatbot]) msg.submit(rinna.chat, [msg, chatbot, max_token_length, min_token_length, temperature], [msg, chatbot]) demo.launch()
たったこれだけです。びっくりするくらい簡単にできてしまいました。
セルの出力にローカルとパブリックのURLおよびGradioのUIが表示されているので、そちらで実際にチャットをすることができます。
実際の画面は以下のようになります。
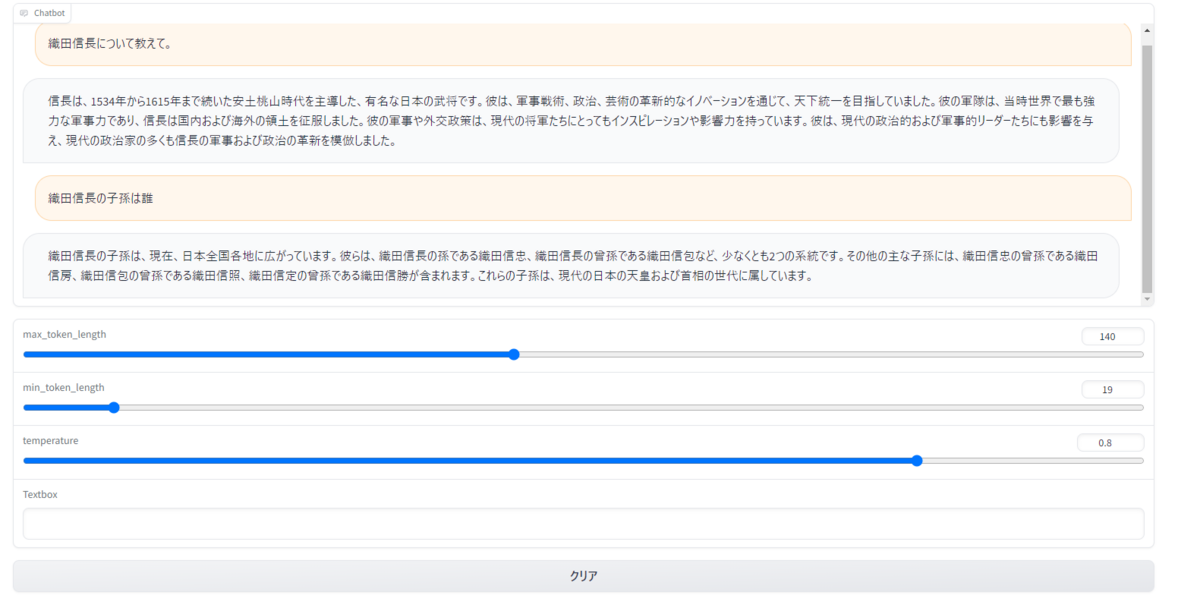 見事にHallucinationを起こしていますが、ご愛嬌ということで…
見事にHallucinationを起こしていますが、ご愛嬌ということで…
というわけでSageMakerとGradioを使ってGPTの簡易デモを作ってみました。
生成モデルの威力もすさまじいですが、Gradioを使うことでここまで簡単にチャット画面を作成することができたことの方が個人的には驚きでした。
皆さんもぜひ活用してみてください。