明けましておめでとうございます。
2023年9月にINGAGEにジョインしたSREチームのanecho108です。
さっそくですが本記事の内容に入りたいと思います。
弊社のサービスは、AWS上のオブザーバビリティを獲得する方法としてNew Relic を利用していましたが、
そこからDatadogに乗り換えました。
Datadogの導入は僕が主体で行っていましたので、その時に考えていたことや反省点をまとめました。
なお、Datadogを肯定するわけでも、New Relicを否定するわけでもございませんのであしからず。
- なぜ乗り換えしようとした?
- そんなところへDatadogから営業メール
- Datadog導入までの流れ
- ヒアリング(数回)
- Datadogにするのか、しないのか、どっちなんだい?
- ざっくり見積
- トライアル
- 契約
- それってDatadogじゃなくても〇〇で出来ませんか?
- 僕が気になっていたこと
- 反省点
- 最後に
なぜ乗り換えしようとした?
New Relicのコスト問題
いくつか乗り換えの理由はありますが、ここが一番の課題ポイントでした。
Datadogでは、機能単位の従量課金+ログ容量であるのに対し、New Relicではフルプラットフォームユーザの人数+ログ容量で料金が決まってきます。
INGAGEではNew RelicのProを利用していました。
そのため、"僕"がオブザーバビリティを獲得したいのであれば、以下にある通り+$418.80(月額)を払う必要があります。
また新しいメンバーが加われば、その分を支払う必要があります。
透明性の高い料金プラン | New Relic
僕の考えとしては、サーバ台数が多ければ多いほどNew Relicの方がお安くなると思います。
さらにそれを(参照するユーザではなく)管理するユーザが少なければ尚良し。1人で数百台を管理するならNew Relicがお得でしょうね。
Datadogは管理する人数による課金はありません。
日本語テクニカルサポートが受けられていなかった
New Relicで日本語テクニカルサポートを受けるには、日本法人での契約が必要です。
ISUCON13 New Relic 支援プログラム | New Relic
また契約には、フルプラットフォームユーザーの最低購入数があるので前述の通り、弊社には難しい状態でした。
最低ラインとして日本語のサポート問い合わせ(AWSのような)があれば良いと考えていました。
今回乗り換えしたDatadogにそこは盛り込まれているのですが、Zoomでの技術的なセッションやチャットでの問い合わせなど
Datadogは契約金額とそのサポートの段階があるので、そこは営業さんに聞いてみてください。
この課題は乗り換えるだけでクリアになった感じですね。
"僕"がオブザーバビリティの獲得に至っていなかった
コスト問題もあり、僕にはNew Relic のフルプラットフォームユーザーが払い出されていない状態でした。
SREチームですので参照権限があっても意味はありません。
また、New Relic のアラート通知先としてSlackを利用しているのですが、なぜこのアラートが飛んでくるか、またアラートの全量がわからず
オオカミ少年化してしまっていて、いまいちオブザーバビリティが見えていない状態でした。
結果的に眺めるのはCloudWatchのダッシュボードになってしまってました。
CloudWatchで必要な情報は取得できますが、トレース情報の連携がなくパフォーマンス調査のアジリティが低い状態でした。
もちろんX-Rayを構築すれば良いのですが、リソースを割けない状態でした。
Application Signals関連がGAされたので今後の成長に期待しています。
周りにDatadogを使ってます勢が多い
弊社CTOと交流のある別会社CTOが利用されているのもDatadogだったり、
私が出席しているカンファレンスでもDatadogの名前を見かけることが多くありました。
また、今のSREチームはDatadogの知見はあれどNew Relicの知見に乏しかったというのも背景にあります。
僕は前職でDatadogの導入検討を進めていて、トレーサーやAgentの設定、サイドカーに組み込む知識など、特にハマる要素はありませんでした。これはNew Relicも同じ仕組みだと思うんですが。
日本リージョンがある
後で知った話なのですが、Datadogには日本リージョンがあります。
会社のポリシーによっては嬉しい情報かもしれませんね。
下記のブログによりますと、New Relicは11月時点では日本リージョンはありません。
ZabbixからNewRelicに移行した話 #zabbix - Qiita
そんなところへDatadogから営業メール
忙しいので優先度を下げてしまっていたオブザーバビリティですが、
これらの課題を抱いている矢先にDatadogの営業メールが弊社CTOに飛んできて話が進んでいきます。
僕は、このときばかりはオブザーバビリティの獲得チャンスだと思いました。
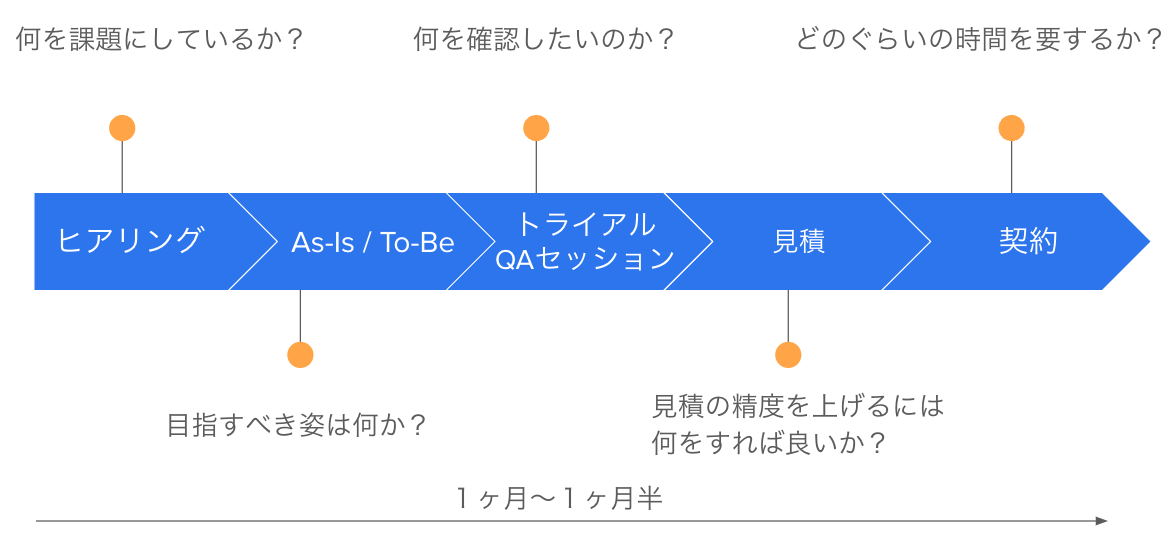
Datadog導入までの流れ
ざっくりまとめると導入までの流れは以下のようなフローを辿っていました。
それぞれのフローではDatadogの営業さんと連携をして、課題やゴールというのを認識合わせしていました。
見積以降は主に僕の話なのですが、ボリュームディスカウントが大きい年額前払いにしようと思っていたので見積の精度を重要視していました。
Datadogの営業さんすごいなぁと感じたのが、導入までの課題感、トライアル時のゴール内容を表形式で明示化していただいたことです。
これは僕がステークホルダーと話すのに有り難かったです。これこれ達成したから導入いけるで。と言いやすい状態に持って行ってくれたのは感謝ですね。
ただし、見積のフェーズは難航したので後ほど詳細はお伝えします。
ヒアリング(数回)
Datadogさんから話を聞いてみようということで打合せの調整を実施しました。
気になっている方は気軽に話を聞いてみるだけでも良いと思います。
オフラインイベント等にDatadogさんが出展されている時もありますのでそこから繋げて行くのもありですね。
ヒアリング時、既に僕はミスったのですが、コストに課題があるならば今いくらNew Relicさんに支払っているか や 各AWSサービス(EC2, ECS on Fargate, ECS on EC2, Lambda)のサーバ台数、タスク数、コンテナ数は明確にしておくべきでした。
また、Datadogの機能をある程度下調べしておき、どのサーバに何を使うのかも考えておくべきでした。
コストに大きく関わるAPMは、アプリケーションサーバやLambdaに導入すれば良いので全サーバに入れる必要性はないのと本番環境やステージング環境の環境別に導入するかどうかです。例えば、APサーバが3台あったとして、1台だけDatadog APMを導入するのもありですが、運用管理が面倒なのでやめました。
話を聞くのにここまでせんでええやろ。と思いますが、年額前払いでボリュームディスカウントの割合を大きくしたかったので、早めにコストに関わる情報は出しておきたかったのです。
Datadogにするのか、しないのか、どっちなんだい?
ここの温度感によって、先方も我々も力の入れ具合が違うと考えています。
数回のヒアリングのうち、僕は早い段階でステークホルダーと状況の共有、そして「どうしたらDatadogを導入するのか?」を話し合っていました。INGAGEの強みでもあるフランクに相談できる環境ですので、さらっと本音トークで話せることができました。
結論としては、コストに最も大きな問題を抱えていましたので、それがクリアになるなら導入という結論に至りました。
また、元々Datadogの機能面は知見があったので基本的にはNew Relicと大差はないだろうと考えていました。(でもDatadogのRUMらへんの良さが違うらしい)
Datadogの営業さんとの初回打合せでは、課題感の共有とコストをお伝えしました。
営業さんから現状よりは抑えられると伺っていたのですが、Datadogは機能での従量課金のため半信半疑でした。
このため、僕自身で見積を行うこととしました。
ざっくり見積
導入の確度を上げるためにざっくりと見積を行うこととしました。
Datadogは機能単位とログ容量で課金ですので、まず何の機能を導入するか考えることしました。
オブザーバビリティといえば、以下の3つ代表格でしょうか。
コスト感は公式サイトの機能ごとに記載がありますので、僕がハマったポイントだけお伝えしておきます。
インフラストラクチャー
インフラストラクチャーについて、公式サイトの説明は以下の通りです。
Datadog では、インテグレーションを利用することで、インフラストラクチャーからすべてのメトリクスとログを収集して、統合システムを全体として把握することができます。 AWSサービスと連携することでメトリクスを取得し、Datadog側に表示することができます。 また、650以上のインテグレーションを提供しています。 docs.datadoghq.com
Datadogの料金体系はややこしいですが、公式サイトを元にAWSサービスでいくらかかるか計算していきます。
ECS on EC2(DEAMONタイプ)
※DEAMONタイプは、1コンテナインスタンスが1タスク数となる
ECS on Fargate
EC2
Lambda
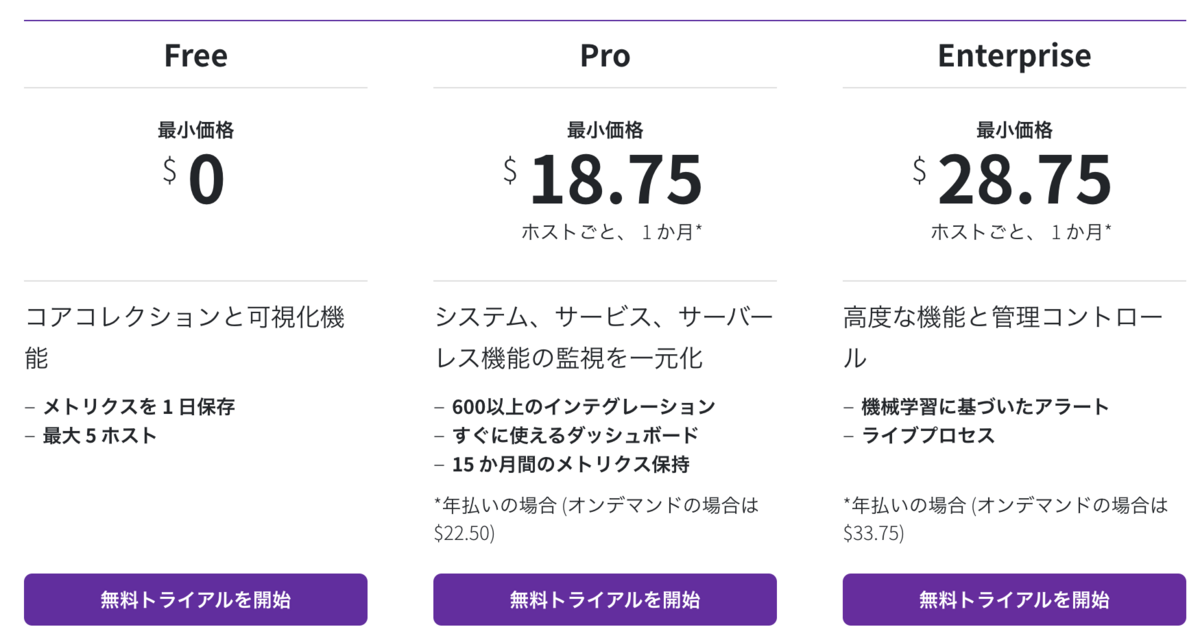
下記のとおり、プランに違いがありますが、Proで進めることとしました。
ホスト
ホストとは、Datadogで監視する物理的または仮想的なOSインスタンスのことです。サーバー、VM、ノード(Kubernetesの場合)、App Service Planインスタンス(Azure App Servicesの場合)などがあります。 ”ホスト”という言葉が僕のような初心者には難しいワードですが つまり、この場合はECS on EC2とEC2をそれぞれ"ホスト"と捉えて良さそうです。 ECS on FargateとLambdaは対象外です。
ECS on Fargateの場合は、"タスク数"に課金があります。 ECS on EC2の場合は、"ホスト"数に加えて"コンテナ"に課金があります。 ただし、1ホストあたり、5コンテナまで無料となります。
ログ
ログについては、”取り込み”と”保存または復元”があります。
”保存または復元”とは、"インデックス"というらしいです。
Datadogでログを参照する場合、
Datadogにログを送るだけでかかる料金=”取り込み”と
送ったログをDatadog上に表示する料金=”保存または復元”
の2種類が支払う料金となります。
計算の単位ですが、”取り込み”はデータ容量(GB/1month)であり、”保存または復元”は、データ件数(100万/1month)になります。
何でもかんでもログを送ってしまうとコスト大になるので、必要なものだけ(ここが難しいんですが)を送ることをオススメします。
また、Datadogに送信する前にERRORのみ送るか、それが難しい場合は一旦全量を”取り込み”をしてから、”保存または復元”時にERRORのみをフィルタリングして表示することで料金を抑える事もできます。 本番環境はERRORのみ、ステージング環境はすべてというようにデータ容量が異なるので環境ごとにわけるのもありですかね。
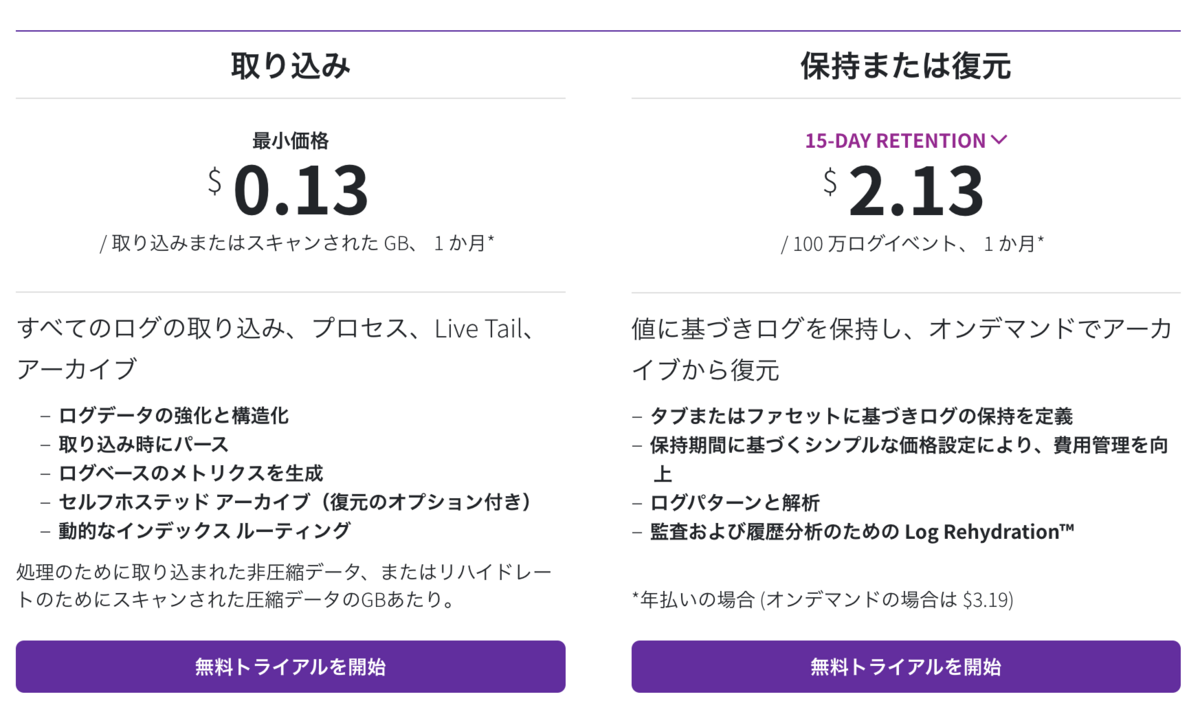
また、以下のように”保存または復元”は保持期間が選択できます。
保存期間が長いほどその分コストはかかってきます。
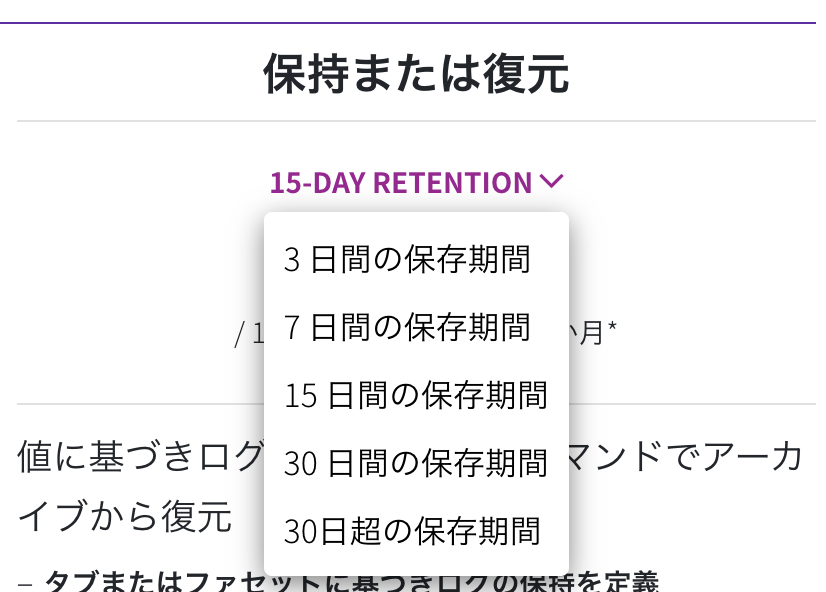
保存期間を過ぎてもログは無くなりません。
ログをS3などにアーカイブすることで長期保存するようですね。
ちなみに何のログを送るか?
弊社では、Sentryを利用しています。Sentryでは、フロントエンドのログやアプリケーションのログを確認できます。
Datadog上のログは、SREチームがオブザーバビリティの獲得して利用することとしました。
つまり、Datadog上ではアプリケーションの一次エラーを確認するのみとして、詳細はSentryに任せる方式を取ることしました。
また、後述Cloud SIEMという機能のためにCloudTrailのログも送ることとしました。
その他にもSREが運用上確認しているログやJSON形式で参照が面倒だったりするログを送る方針としました。
再度ステークホルダーと認識合わせ
このざっくり見積から当初Datadogの営業さんから提示された金額よりもぐっと抑えられてたと思います。 これをもとにまたステークホルダーと話し合い、導入の確度はS~Aかなと認識を合わせました。
そしてDatadogの営業さんには早い段階で以下も踏まえて確度も伝えてました。
コスト$XXXX以下であればOK
機能な機能は備わっているのでOK
サポートについても、受けられるということでOK
トライアル
数回のヒアリングと私のざっくり見積から確度も高くなったため、次のステージに進むこととしました。
トライアルでは事前に営業さんと何をゴールとするか明確化したうえで望みました。
またトライアル中にQAセッションを設けていただいたので疑問点はそこで解消することができました。
Datadogの公式にマニュアルが記載されていたり、Datadogのコンソール画面上からもインストール指示があったので特にハマる要素もなかったかなと思います。
膨らむスコープ、迫りくるトライアル期限
最低限、Datadogの導入にあたって考えていたインフラストラクチャ、ログ、APMでのトライアルのゴールは達成することが出来ていました。
一部営業さんから押しもあってトライアルがスタートしてから、主要な機能以外も触れてみることにしました。
CloudSIEM
CSM
ASM
RUM(リアルタイムユーザモニタリング)
Sytheticモニタリング
※インシデント管理については、AWSのIncident Managerで良いかなと思っていたので除外しています。
結果的に上記はこれからの弊社サービスの成長度合いも踏まえて導入することとしました。理由としては、使っていてUIが良かったのと弊社の課題と感じている部分が見える化できたためです。
RUMについては、そのまま素直に利用すると高額となってしまいますが、N%だけデータを取得するというサンプリング設定を行うことでコストを抑えることとしました。
ただし、トライアル期限が迫っていて検証をすべて実施することは出来ませんでした。営業さんに相談すれば多少は期限を伸ばすことも可能でしたが、日常的なSRE業務もありましたので断念しました。
これらの見積は膨らんだスコープに加えて、AWSサービスごとに計算方式が異なるので大変でした…。
契約
なんだかんだありましたが見積以降はすんなりと契約まで流れていきました。
正式見積から自社での契約の流れと決裁が下りるまでの期間も把握しておいたのでそれが良かったのかなと思います。
ただ、今回僕が主体で行っていましたので日常のSRE業務に加えて、トライアル作業と正式見積に向けた数値出し作業はタイトだったかなと感じています。ちなみにトライアルのアカウントのまま契約することも、作り直すことも可能だそうです。
AWSのマーケットプレイスで買ったら?
支払いをAWSにまとめたい、決裁取るのがめんどくさい。そういった理由からAWSマーケットプレイスを使うことも可能です。
今回の流れを踏まえるとQAセッションもあり、疑問点を解消しながらトライアルを進められたのでDatadogの営業さんとやり取りしながらで良かったなと考えています。
それってDatadogじゃなくても〇〇で出来ませんか?
SREチームはメンバー募集中のため、オブザーバビリティに人をかけられない状態です。
ですので、AWS上でビルディングブロックを組めれば確かに実現できる機能もあったりしますが、UI、コスト、問題発見と原因解決のしやすさや人のリソースを天秤にかけて選択しています。
例えば、後述するCSMについてはSecurityHubとほぼ同義です。しかし、セキュリティ基準に準拠しているか、NIST等もカテゴリごとに分類してくれてUI上もわかりやすい感じでした。
またインシデント管理でいえば、PagerDutyやAWSのIncident Managerという選択肢もあります。これらを踏まえつつ、未GAのためカバー範囲が不足している機能だったり、許容できないコストはDatadogから除外することとしました。
それでも魅力的な機能は、他を削って使うよう見積もりに含めました。それって〇〇じゃ出来ませんか?という観点は大事だと思いますので、この考えも踏まえて検討を進めていくべきだと思います。
僕が気になっていたこと
ここからは僕が気になっていたことを簡単にまとめました。
ECS on EC2はECSコンテナインスタンスだけにDatadog Agentをインストール?
ECS on Fargateの場合であれば、サイドカーとしてDatadog Agentのコンテナを存在させるのが一般的ですが ECS on EC2であれば、やり方は次の2通りあるようです。
EC2コンテナインスタンスにDatadog Agentをインストール
Datadog Agent コンテナ用のタスク定義を作成し、それをDEAMONとしてデプロイ
以下の記事を参考にさせていただきました。
engineering.cocone.io
公式では後者のようです。
https://docs.datadoghq.com/ja/containers/amazon_ecs/?tab=awscli
ECS on EC2はAutoScalingと連携しており、Datadogの設定頻度も少ないことから、cloud-initでDatadog Agentをインストールする方式にしようと考えています。
前者ですとCSMではコンテナ側の情報を取得できないようでしたので後者で実装する必要があります。
ホスト数ではなくホスト名でカウントされてしまうのか?
EC2のAMIを更新するとEC2のホスト名は変わってしまいます。
いちお気になったので、聞いてみましたがホスト数とのことです。
1時間に1回、Datadog側がホスト数を数えているようです。
ホスト数も1ヶ月あたりの99%タイルで課金があります。
ですのでスパイクで台数が増えてもそれは無視される可能性が高いですね。
詳しくは下記を参照していただければと思います。
料金
AWSアカウント分離でコスト影響があるか?
今回、見積もり上にAWSアカウントから分離したいサービスがあったのですが
これを分離したとしても影響はないとのことです。ホストで数えていますので当たり前ですね。
年払いで月額費用に満たない場合は繰越しがあるか?
ありません。
ですので年額ギリギリで攻めて、溢れた分はその年の従量課金の金額で支払うこととなります。使っていれば、どうせ大きくなるのでまた見直しかもしれません。
CSMって何?
CSM(Cloud Security Management)は、いくつかの機能が含まれていますが主たる機能はSecurity Hubと同義と捉えて問題なさそうです。事前にCloud SIEMというCloudTrailログをDatadogに送信して解析する設定が必要です。
それ以外の機能もありましてCWS(Cloud Workload Security)は、いわゆるIDSとのことです。DatadogでThreatsという呼称となります。
ウィルス対策ソフトは不正ファイル配置の検知と疑わしい挙動を検知してくれますが、IDSは疑わしい挙動のみです。
試しにEICAR テストファイルを配置したのですが、CWSは特に何も反応しませんでした。
こちらFargateは2023年12月時点では未対応です。
Vulnerabilitiesは、その名の通り、脆弱性検知の機能となります。
CSM Proはコンテナのみであり、+ホストも検知したい場合はCSM Enterpriseが必要です。
こちらもFargateは2023年12月時点では未対応です。
Identity Riskは、CloudTrailをDatadogに連携することでIAM関連の情報を表示してくれます。IAM設定不備だったり、いつから存在しているか追跡できます。CSM Enterprise or CWSのみの機能となります。このIAMポリシーはNか月前に存在していて誰も使ってないのに、アドミン権限あるでとかがわかります。
トライアルで確認したのですが、これらの機能はUIが良いと思いました。
Vulnerabilitiesは、脆弱性単位でどのサーバで存在するのか一括りにしてくれて、さらにJiraに連携できます。
こうすることでアプリケーションチームへのタスクとして盛り込めて便利そうでした。
Fargateが近々GAされる噂も耳にしたので期待したいところです。
ASMって必要?
AWSのカンファレンスに出席すると、多層防御というキーワードを聞いたことがあるかもしれません。
AWS WAFとASM(Application Security Management)を利用することで多層防御を実現できます。
恥ずかしながら僕はCloudFrontとALBにWAFをそれぞれ入れれば多層防御なん?意味ある?と勘違いしてました。全然意味ないですね。
反省点
営業さんとの認識のズレ
営業さんと言葉の認識がズレることがありました。
例えば、”インフラストラクチャー"という言葉でして、Datadog上は機能を表すのですが、僕は"インフラ"として誤解してしまいました。
オブザーバビリティ界隈では、インフラストラクチャーとは一般的かもしれませんね、僕が勉強不足だったのかも。ごめんなさい。
このせいでヒアリング当初、話がズレてて私は混乱してました。
課金体系の複雑さ
Datadogの課金体系は複雑だったと感じています。
さらに各AWSサービスによっても計算が異なるので、ここは営業さんと連携して正確な見積を出しましょう。
公式サイトを確認すればある程度は理解できるかもと思って、一番最初に私が作成したざっくり見積は、ほぼ計算間違ってました。
インフラの台数を把握しておく
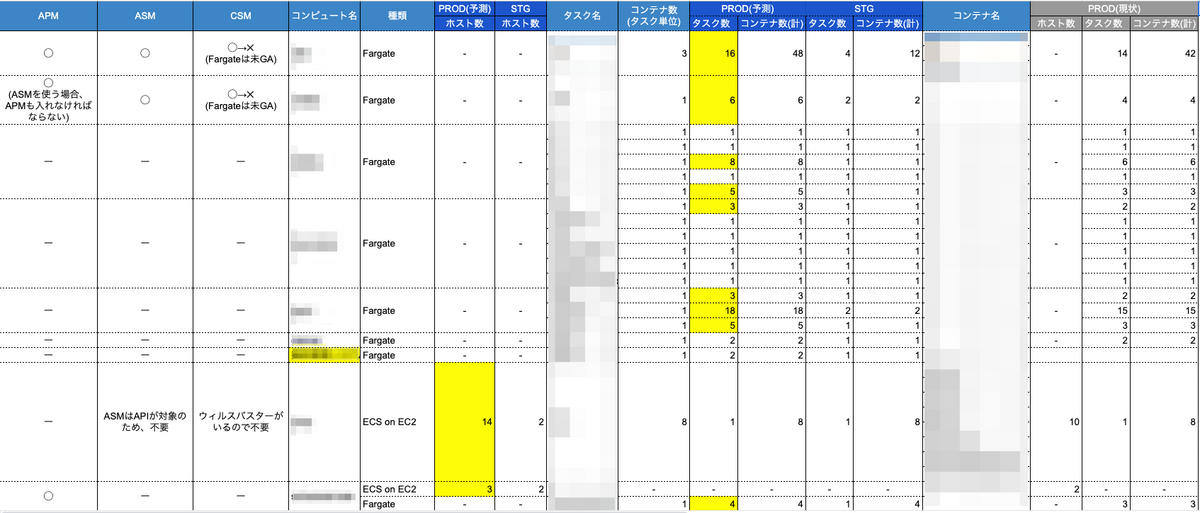
Datadog との初回打合せ付近でサーバ台数、タスク数、コンテナ数、Lambda数、ログサイズとログ件数を調べておくと良かったなと思いました。特に本番以外にも必要な部分は含めておくべきでした。また、今回は年額前払いですのでサービスの成長度合いも加味したサーバ台数を見積もる必要があり、最終的な見積の段階で、以下のようにサーバ台数やタスク数、何を導入するかを決めました。
このレベルまで落とし込めておけば楽だったなあと感じます。黄色セルは成長込みで現状より増やした箇所です。
Datadogの機能面
Datadog の機能は何があるかを抑えておくべきでした。
インフラストラクチャ
ログ
APM
CloudSIEM
CSM
ASM
RUM
Syntheticモニタリング
インシデント管理
コスト面で導入しないで良いかなぁと思っていた部分もコストを抑えるテクニックや運用で削減できることもあって、導入しよう!という考えにも至ったので最初から決めつけは良くないことだなあと感じました。
OpenTelemetly
本記事では触れませんでしたが、リソースに余裕があればOSSのOpenTelemetlyを利用して実装するのも良いかもしれません。
最後に
最後までお読みいただきありがとうございます。
弊社がNew RelicからDatadogに乗り換えした話を書かせていただきました。
これからオブザーバビリティの獲得に向けて考えているSREの方や弊社と同様の課題感をお持ちの方に本取り組みが少しでもお役に立てればと思います。
(2024/04/15) その後の導入時のブログも書かせていただきました
Datadog導入時の備忘録 - インゲージ開発者ブログ