SREチームのanecho108です。
前回は、New RelicからDatadogに乗り換えした話を書かせていただきました。
ブログを書いてから数ヶ月経ちましたので、Datadogの導入時に実施したことを備忘録として書かせていただきたいと思います。
- Integrations設定
- Infrastructure List
- Metrics
- Logs
- Datadog Agentの導入
- Atlassian StatuspageにDatadog日本リージョンがない
- Datadogのユーザ追加
- ダッシュボードの作成
- コストの確認
- 最後に
Integrations設定
まずDatadog導入時の最初に設定すべきこととして、Integrationsの設定があります。 こちらはAWSとDatadogを連携する設定であり、設定するだけでメトリクス情報等を取得することができます。
Integrationsの設定方法は自動と手動の2種類
AWSとのIntegrationsの設定方法として、自動と手動の2種類があります。自動の方はCloudFormationで設定してくれるようです。 CloudFormationを見れば何をしているかはわかるものの、IaC化したかったために今回は手動設定を行っています。
手動設定は、IAMロールに外部 IDを設定して信頼されたエンティティとして信頼関係を設定します。資格のAWS SAPやFTRにベストプラクティスとして出てくる内容ですね。
手順については下記Datadogのドキュメントに詳細が記載されていましたのでこちらを参照しながら設定しています。 docs.datadoghq.com
Datadogを使うリージョンを間違えないように
上記のドキュメントには、IAMロールに設定するDatadogのAWSアカウントと外部IDが記載されています。 Datadogドキュメント上でDatadogを使うリージョンを間違えないようにしておきましょう。
Datadog のAWSアカウント IDは、リージョンごとにあるようでこちらの選択を間違ったままですと、ドキュメント上に記載されているDatadogのAWSアカウントもそのリージョンでのIDとなっており、連携できません。

Datadog関連のセキュリティを扱うのであれば+SecurityAuditを付与
上記マニュアルに設定すべきIAMポリシーが記載されていますが、Cloud SIEM等のDatadog関連のセキュリティを扱う場合はIntegrationsに設定するIAMロールに加えて、セキュリティ関連のポリシーを付与して上げる必要があります。
![]()
Terraform化できる
弊社ではDatadogを使っていく最初の時点からIaC化したかったため、設定はTerraformのDatadog Providerを使いました。
registry.terraform.io
CSMの設定
AWSのSecurity Hubと類似しているCSMを利用する場合、アカウント連携するとすべてを対象として取得してくれます。
一部のみのサーバのCSMを利用したい場合は、コストがコミット分以上に跳ね上がりますので注意しましょう。
そういった場合は、Datadog Agent側から設定すれば良いと考えています。
弊社ではCSMは未設定ですので、詳しくはマニュアルをご参照していただければと思います。
Infrastructure List
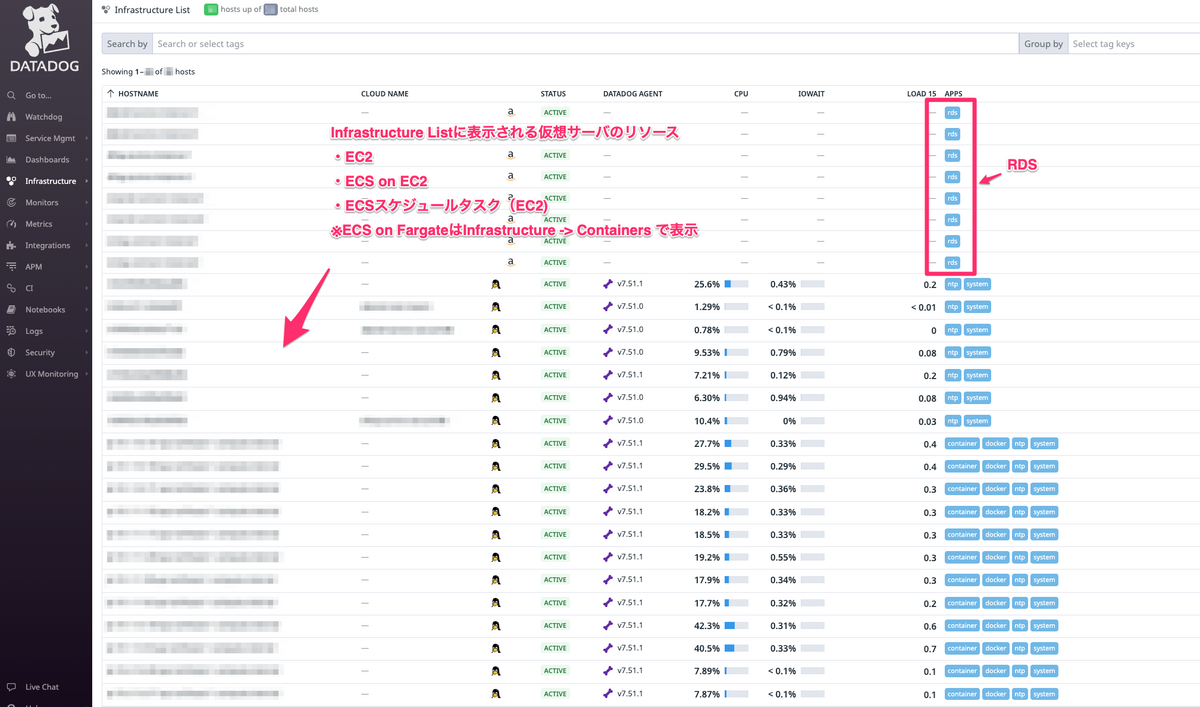
Integrationsの設定が完了して少しすると、Infrastructure Listにサーバリストが連携されていることがわかります。 設定するだけで殆ど見えるようになります、凄いですよね。
こちらの画面では、サーバリストが見えており、サーバレスは見えません。
Infrastructure ListはEC2等のサーバ以外にもRDSなどが含まれています。各サーバを選択することでそれぞれのメトリクスを確認できます。
Metrics
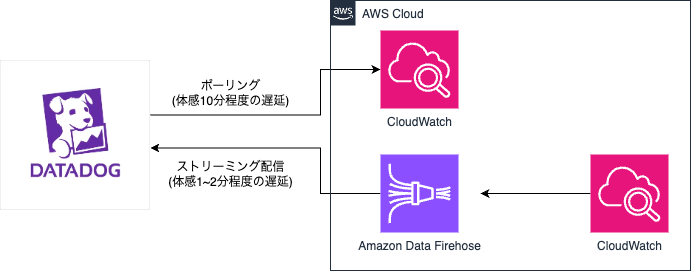
Datadogにメトリクスを送信する方法としては、大きく2つあります。
下記キャプチャのようにDatadog側がCloudWatchにポーリングする方法とAmazon Data Firehoseを利用する方法です。
前者についてはAWSアカウントのIntegrationsを設定した状態だと既に有効になっていてメトリクスは取得できていると思います。
両者の違いとしては、前者の遅延が大きいです。Datadog側でAWSのメトリクスを確認やアラートを発火する際、遅延が少ない方が良いためAmazon Data Firehoseからストリーミングするよう設定しました。
Amazon Data Firehoseは、送信先にデフォルトでDatadogが選択可能となっており、必要な認証情報を設定しました。CloudWatchからはメトリクス -> ストリームで前述のAmazon Data Firehoseを指定しました。
Integrations上の見え方
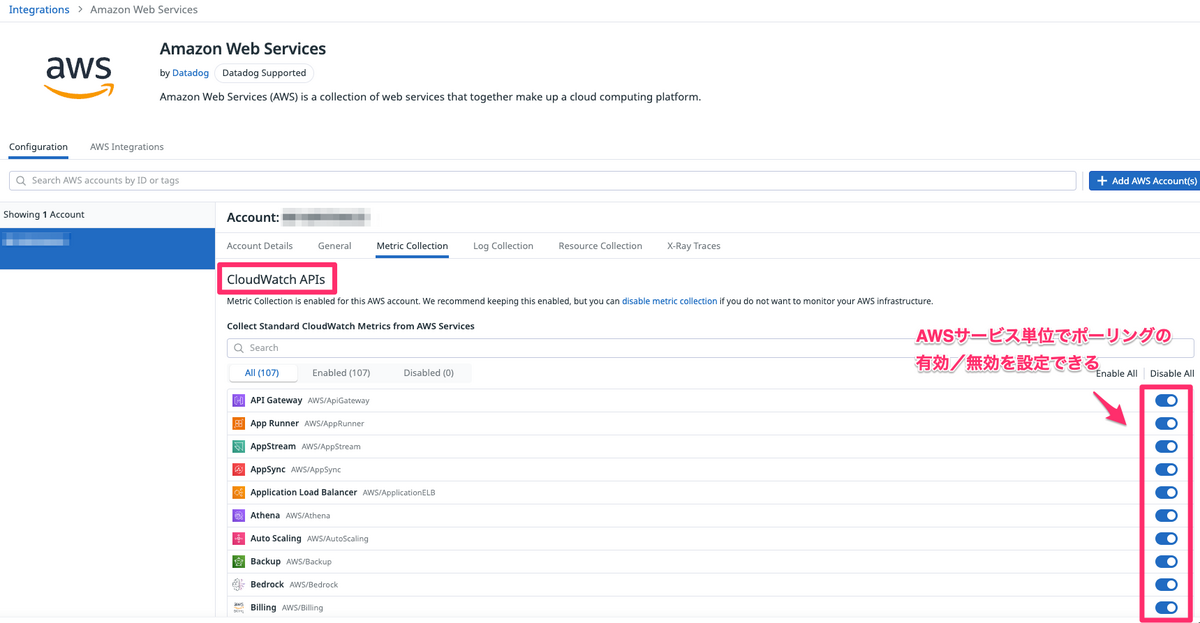
先ほど設定したIntegrationsの画面からMetric Collectionタブを参照すると、この2つの設定を確認することができます。
ポーリングする方法
CloudWatch APIsでポーリングする設定を確認することが出来ます。
Amazon Data Firehoseからストリーミングする設定も加えている場合、Datadog側が自動的にストリーミングを優先してくれると思います。
本ポーリング設定は有効にする必要もないので無効にしようと思ったんですが、Amazon Data Firehoseからストリーミングする方法ですと
取得できないメトリクス(例えば、aws.ecs.running_tasks_count)があり、ポーリングする方法は基本的には無効にしなくても良いと思います。
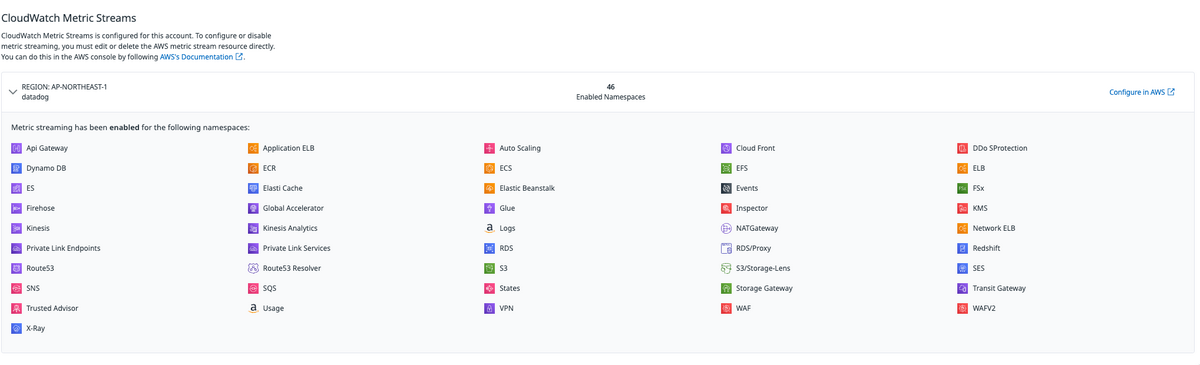
Amazon Data Firehoseからストリーミングする方法
Amazon Data Firehoseからストリーミングする設定を行うと、上記画面を下の方にスクロールして確認できます。こちらはCloudWatchのメトリクスストリームで設定した内容が反映されていると思います。
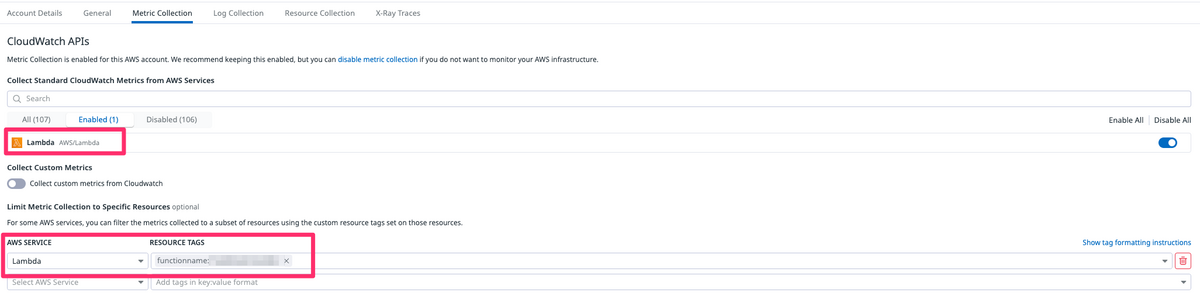
Lambdaはストリーミングを無効
Lambdaについては、Amazon Data Firehoseからのストリーミング設定は無効にしてポーリングを有効しています。
特定のLambdaだけをDatadogで監視するために、ポーリングを有効にしており、キャプチャのように関数名でフィルタリングしてメトリクスを取得しています。
これは、Amazon Data FirehoseからのストリーミングではLambdaのフィルタリングができず、全てのLambda関数がインフラストラクチャーの対象となってしまうからです。
Lambdaのインフラストラクチャーには料金がかかりますので、監視不要なLambdaにもコストがかかってしまうのを避けるためですね。
Logs
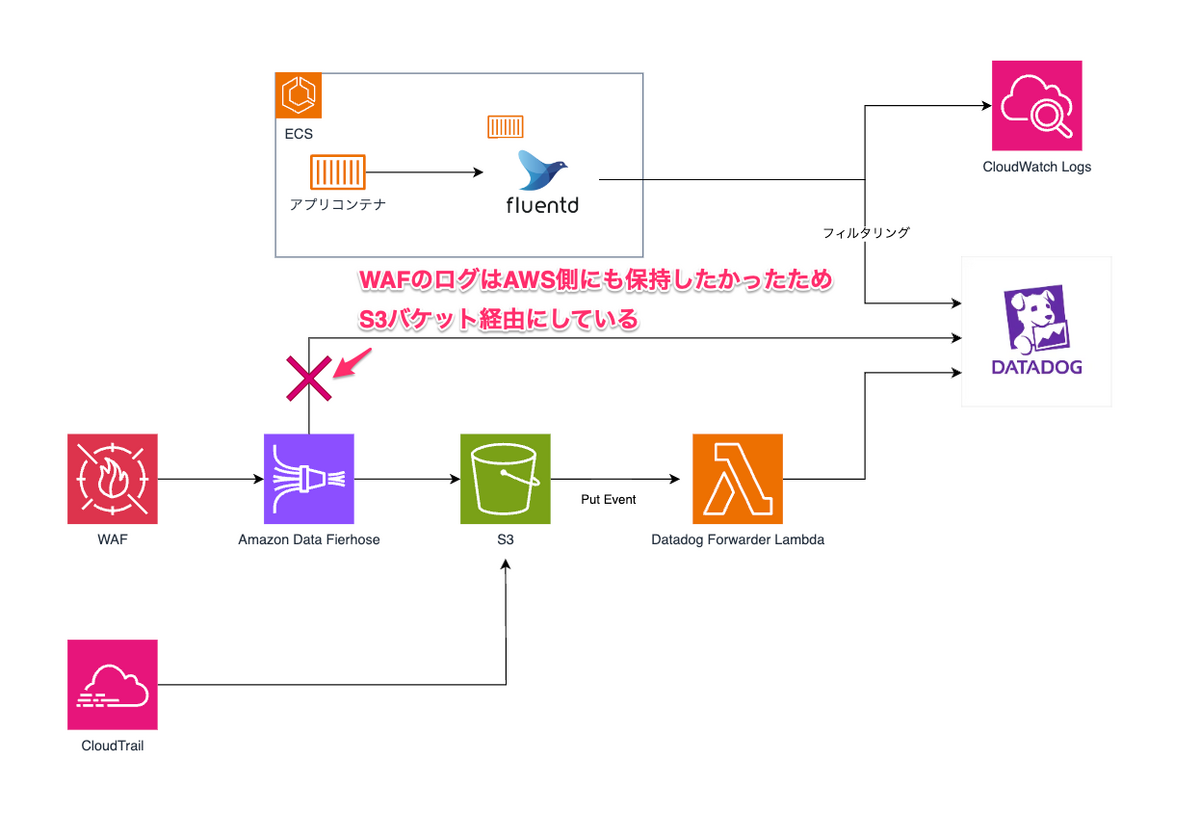
Datadog側にログデータを送信する方法は以下の3パターンを考えました。
- fluentd経由
- Datadogから提供されているDatadog ForwarderのLambda関数を経由
- Amazon Data Firehose経由
コスト削減を意識
Datadogのコスト削減を踏まえて、ログは必要なもののみを送信するか、送信した後にDatadogでフィルタリングするかを考えました。 また、Datadog上には長く保存しない方針にしたため、AWS側に保存したいと考えました。
重要度の高いログについては、結果的には下記のキャプチャの流れとなりました。ゆくゆくは増やしていきたいですね。 また、CloudWatchにログを送信するのにコストもかかるので、こちらはS3に寄せるよう改善を検討しています。
Datadog Agentの導入
Datadogのドキュメントに記載がある通り、ECS on EC2はECSサービスとしてDatadog Agentを立ち上げるのに対してECS on FargateはコンテナのサイドカーとしてDatadog Agentを導入しました。
Pull through cache 設定
Datadog Agentイメージは意外に大きく、ECSのタスク定義にPublic Registryから直接取得して記述すると、NATゲートウェイのコストにかかってきます。
また、DevOpsや生産性向上のためにリリースサイクルが毎日ですとより無視できないものだと思います。
このため、ECRにPull through cache 設定をすることでイメージのキャッシュを行っています。タスク定義はPull through cacheのリポジトリから取得するよう設定しました。
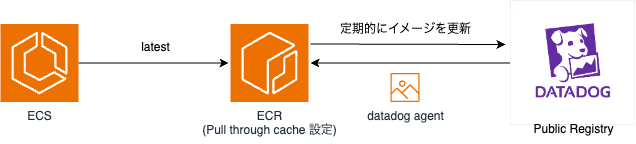
Pull through cacheに必要なIAMポリシーは下記になります。
CPUやメモリはどのぐらい増やすのか?
上記のドキュメント内のタスク定義のjsonファイルがありました。
"cpu": 100, "memory": 512,
だいたいこんなものかなとも思います。
AWS上ではCPU 0.1という定義はないので、CPU 0.5とMemory 512MBを増やす方針にしました。
Datadogの導入前後ではCPUとメモリのメトリクスに変動はありました。
現在運用中ですが様子見をしています。
パフォーマンスに影響があるのか?
前職でもパフォーマンスは多少の影響がありました。今回の導入でも数十ms程度の違いはありましたね。
トレース情報はログ出力のようなものですからその分の影響はあると考えています。
Atlassian StatuspageにDatadog日本リージョンがない
弊社では、Statuspageを使って自社Saasアプリケーションの状況を配信しています。 アプリケーションのメトリクスを配信することで、お客様にも見える化しています。
今まではNew Relic上からメトリクスを連携しており、Datadogに移行しましたので変更しようとしたのですが、設定画面の選択肢にDatadog日本リージョンがありませんでした。
色々と調べましたが結果的に設定変更が出来ませんでしたので、Datadog側にもAtlassian側にも追加して欲しいリクエストを投げております。早く対応されると嬉しい限りです。
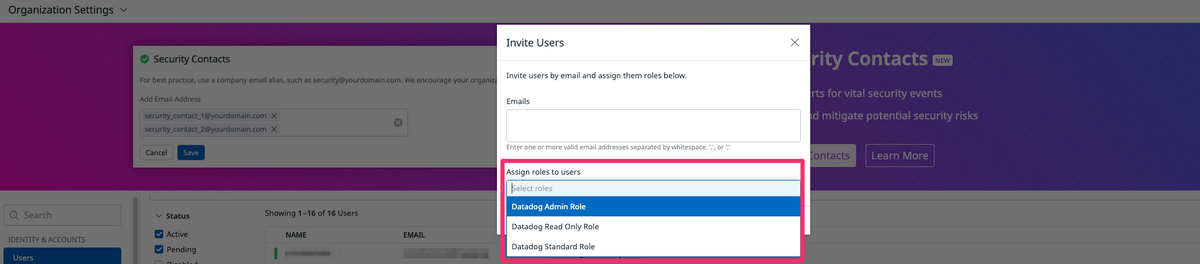
Datadogのユーザ追加
デフォルトで3つのロールが用意されており、ロールはカスマイズ可能です。開発部向けに展開するためにひと通りユーザを追加しました。
Datadogではユーザによる課金はありませんのでありがたいですね。
ダッシュボードの作成
デフォルトで多くのダッシュボードが提供されています。
ダッシュボードをクローンすることで、どのように設定されているかを確認することもできます。
ご自身で作りたいメトリクスとその設定を確認しながら作るのが良いと思います。 ダッシュボード画面からJSONを出力することができますので、画面上で作ったものをTerraformに反映することも可能です。
慣れてきたらTerraformのみで作るのもありと考えています。
コストの確認
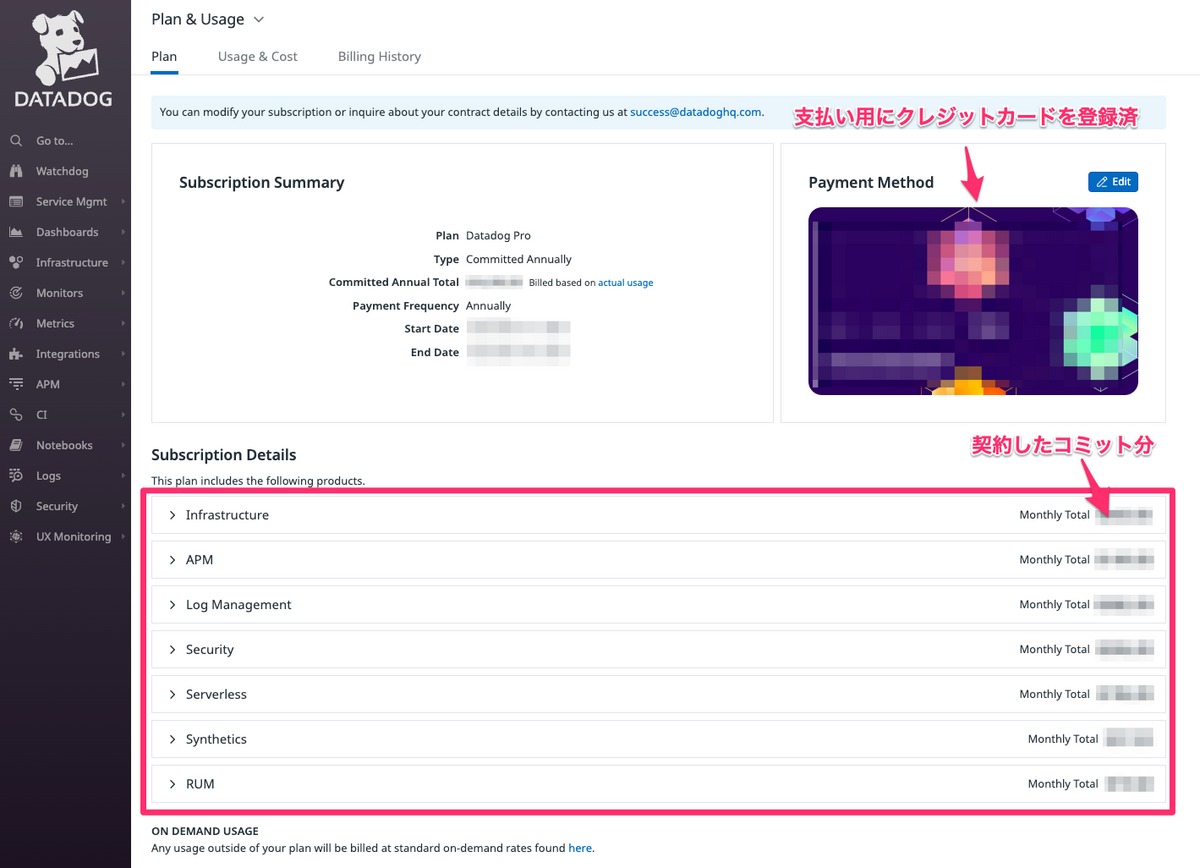
メニューからご自身のアカウントをクリックして、Plan & UsageにてDatadog上のコストを確認することができます。
Planタブ
こちらでは事前にコミットした分の状況を確認することができます。
Datadogの営業さんからいただいた見積書を照らし合わせながらが良いと思います。
Usage & Cost
こちらでは現状のコスト状況を確認することができます。
設定ミスや見積ミス等で発生したオンデマンド料金を確認したり、想定外のコストを把握することができます。
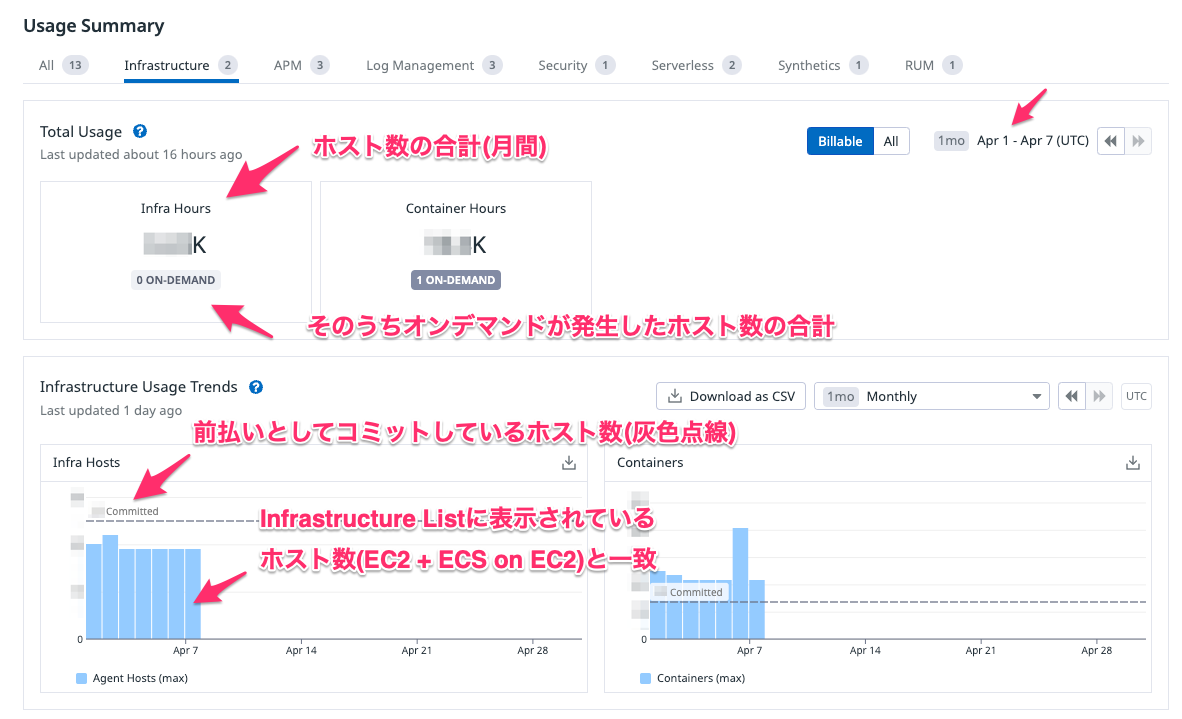
Infra Hostsを例に確認
Infra Hostsを例にあげると下記キャプチャのようになります。
Infra Hostsは、Infrastructure ListのEC2およびECS on EC2のホスト数となります。
※Fargateの方はContainers側に含まれます。
特に確認すべきは、コミット分以上にコストが発生していないかですかね。
下記でdatadog.hogehoge系のメトリクスでそういった情報も取得できそうですね。
推定使用量メトリクス
Usage & Cost
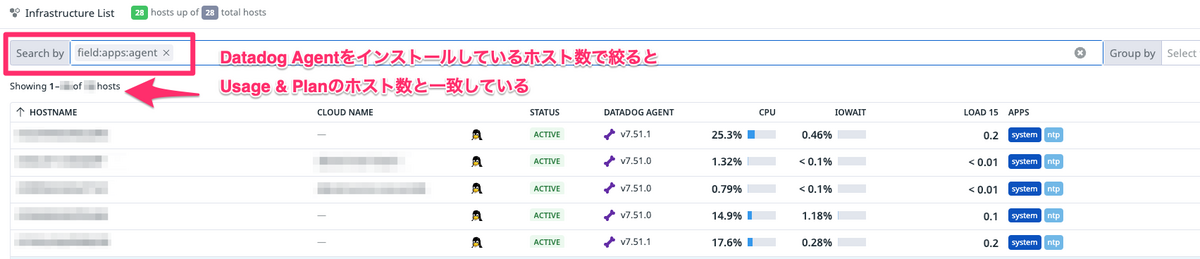
Infrastructure List
Infrastructure ListでDatadog Agentをインストールしているサーバ数を確認するとUsage & Cost側と一致していることがわかります。
※台数はモザイク処理をしています、ご容赦ください。
コンピュートサービスの計算おさらい
AWSでコンピュート系は、大きく4種類あります。
以下の各①〜③は、同義の課金体系になります。
・EC2:① ・ECS on EC2 -> EC2:① -> タスク数:② -> コンテナ:③ ・ECS on Fargate -> タスク数:② -> コンテナ:③ ・Lambda:④ ※③のコンテナ無料分は弊社の契約時点で =③の合算 − ①の合算x5 のコンテナ数が課金。ただし、Datadog自体のコンテナは除く。
こちらを踏まえてInfrastructure -> ContainersからDatadog Agentのコンテナを差し引いてみると範囲時間によってブレはありますが、だいたい合っていました。
最後に
最後までお読みいただきありがとうございます。
弊社がDatadog導入時に設定した内容を書かせていただきました。
本内容が皆様の取り組みに少しでもお役に立てればと思います。